
Cours
Introduction
L'informatique est utilisée de nos jours pour le traitement de quantités importantes de données : commerce en ligne, bases de données pour des dizaine de milliers d'articles du commerce en ligne, des millions de clients, de commandes, etc.
Les systèmes de gestion de base de données sont des programmes hautement spécialisés pour effectuer ce genre de tâches mais nous allons voir dans ce cours qu'il est facile de mettre en œuvre les opérations de base de ces système dans un langage de programmation comme Python.
Les bases de données relationnelles (BDR) qui contiennent un ensemble de tables (appelées relations) et le langage SQL permettant d'effectuer des requêtes dans ces tables ne seront étudiées qu'en terminale NSI.
Vocabulaire
Une table est un ensemble d'objets appelés enregistrements.
Un enregistrement possède différentes valeurs associées à des attributs (descripteurs).
Toutes les valeurs que peut prendre un attribut s'appelle son domaine de valeurs.
| nom | prénom | classe | ← les attributs |
|---|---|---|---|
| BOUDOT | Nathan | 705 | ← chaque ligne = un enregistrement |
| PICHOU | Elvis | 703 | ← chaque ligne = un enregistrement |
| ZITA JOAO | Brandy | 704 | ← chaque ligne = un enregistrement |
| LAGUEB | Amine | 705 | ← chaque ligne = un enregistrement |
Le format CSV
- Le caractère de séparation est majoritairement une virgule dans le monde anglo-saxon mais en France où la virgule est utilisée pour les nombres décimaux, il lui est préféré le point-virgule.
- Un fichier CSV peut être lu par un éditeur de texte mais aussi un tableur.
ISO-alpha2;ISO-alpha3;ISO-numeric;fips;Country;Capital;Area;Population;Continent
AD;AND;20;AN;Andorra;Andorra la Vella;468.0;84,000;EU
AE;ARE;784;AE;United Arab Emirates;Abu Dhabi;82,880.0;4,975,593;AS
AF;AFG;4;AF;Afghanistan;Kabul;647,500.0;29,121,286;AS
AG;ATG;28;AC;Antigua and Barbuda;St. John's;443.0;86,754;NA
AI;AIA;660;AV;Anguilla;The Valley;102.0;13,254;NA
AL;ALB;8;AL;Albania;Tirana;28,748.0;2,986,952;EU
...Importation d'une table depuis un fichier CSV
Le module natif csv de Python permet d'importer les données depuis un fichier CSV.
Voici un script permettant de charger le fichier countries.csv avec des points-virgules comme délimitations.
import csv
with open('countries.csv', newline='', encoding='utf-8') as csvfile:
pays = list(csv.reader(csvfile, delimiter=';'))1 - Récupérer le fichier .
2 - L'explorer avec un éditeur de texte et identifier chaque descripteur.
3 - Exécuter le script ci-dessus (il devra être placé dans le même dossier que countries.csv).
4 - Qu'affiche l'instruction
pays[0] ?
5 - Qu'affiche l'instruction
pays[1] ?
- On s'aperçoit que la première ligne (des descripteurs) est traitée comme les autres (les enregistrements).
- Les valeurs du 1re enregistrement (concernant l'Andorre) ne sont pas associées directement à leur descripteur. Pour y remédier et pouvoir faciliter le traitement des données, il est préférable que celles-ci soient sous forme d'une liste de dictionnaire, plutôt qu'un simple tableau (liste de listes) comme dans l'exemple suivant :
import csv
with open('countries.csv', newline='', encoding='utf-8') as csvfile:
pays = list(csv.DictReader(csvfile, delimiter=';'))1 - Exécuter le script ci-dessus (il devra être placé dans le même dossier que countries.csv).
2 - Qu'affiche l'instruction
pays[0] ?
5. Rechercher dans une table
Un critère est une condition appliquée à la valeur d'un attribut d'un enregistrement.
resultat = [p['country'] for p in pays if p['continent'] == 'EU'] resultat.resultat = [p['continent'] for p in pays] resultat.On obtient une liste avec beaucoup de répétitions. Pour supprimer tous ces doublons, il est possible de transformer cette liste en un ensemble (appelé set en anglais).
La fonction native set() permet de convertir une liste en un set pour éliminer les doublons.
resultat = set([p['continent'] for p in pays])
1 - Exécuter l'instruction ci-dessus et afficher le contenu de la variable
resultat.
2 - Associer chaque code à un des 7 continents.
6. Trier une table
En effet, il est beaucoup plus efficace (rapide) d'effectuer une recherche dans une liste triée. Cela vient du fait qu'il est alors possible d'effectuer une recherche par dichotomie. Cet algorithme de recherche par dichotomie, ainsi que différents algorithmes de tri seront étudiés dans un prochain chapitre.
6.1. Trier selon un unique critère
Pour cela, on appelle la fonction
sorted(list) (voir doc python) qui retourne une copie de la liste triée ou la méthode list.sort() (voir doc python) qui trie la liste sur place.
Ces deux fonctions ont deux paramètres possibles :
keyqui est la fonction permettant d'évaluer les éléments de la liste afin de les classer selon leur scorereversequi est un boolean (par défautFalse) permettant de trie selon l'ordre décroissant (True).
Par exemple, si l'on veut trier les pays selon leur superficie : il faut d'abord définir une fonction qui permet d'accéder à la valeur de l'attribut 'area' d'un enregistrement puis retourne le score de l'enregistrement afin qu'il puisse être comparé aux autres et ainsi trier la liste entière.
def cle_superficie(p):
return p['area']
pays.sort(key=cle_superficie, reverse=True) # tri
top5 = [(p['country'], p['area']) for p in pays[:5]] # extraction
for p in top5 : # affichage
print(p)1 - Ajouter le script ci-dessus à la suite de l'importation des données (script précédent) et l'exécuter.
2 - Comprendre ce que réalise chaque instruction de ce script et l'adapter pour qu'il affiche également le continent du pays.
3 - Les 5 pays affichés ne sont pas ceux ayant la plus grande superficie ? Donner une explication au problème ?
4 - Corriger ce problème.
Tri selon plusieurs critères
def cle_continent_pop(p):
return (p['continent'], p['population'])- trier tous les pays par populations décroissantes,
- trier ensuite le tableau obtenu par continents croissants.
def cle_population(p):
return int(p['population'].replace(",", ""))
def cle_continent(p):
return p['continent']
pays.sort(key=cle_population, reverse=True) # tri par population
pays.sort(key=cle_continent) # tri par continent
resultat = [(p['country'], p['continent'], p['population'])
for p in pays if int(p['population'].replace(",", "")) >= 50000000] # extraction
for p in resultat : # affichage
print(p)- Afin de comparer les populations, il a fallu effectuer un traitement des données en remplaçant les virgules de la chaîne de caractère et en changeant le type.
- Pour que cela soit possible, la fonction de tri de python vérifie une propriété très importante : la stabilité. Si plusieurs enregistrements ont la même clé, l'ordre initial des enregistrements est conservé. Ainsi, si on a trié les pays par ordre décroissant de population puis par continent, les pays d'un même continent seront regroupés en conservant l'ordre précédent.
1 - Ajouter le script ci-dessus à la suite de l'importation des données et l'exécuter.
2 - Comprendre ce que réalise chaque instruction de ce script et en particulier la ligne 9.
3 - Le script ci-dessus n'est pas optimal (tri multicritère suivi de l'extraction). Améliorer le script pour qu'il soit plus rapide.
7. Fusionner des tables (Jointure)
7.1. Fusionner des tables ayant les mêmes attributs
Les données étant importées sous la forme d'une liste. Fusionner deux tables revient à concaténer deux listes.
La dernière étape est de sauvegarder cette nouvelle liste de dictionnaire dans un nouveau fichier CSV 'nom_fichier.csv',
ce qui est réalisable avec le script suivant :
with open('nom_fichier.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = list(liste_fusionnee[0].keys())
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter=';')
writer.writeheader()
for p in liste_fusionnee:
writer.writerow(p)- La liste fusionnées est dans la variable :
liste_fusionnee. - L'argument
'w'donné à la fonctionopen('nom_fichier.csv', 'w', newline='', encoding='utf-8')permet d'ouvrir le fichier en mode écriture (write). Par défaut ce paramètre est en mode lecture ('r'pour read).
Le fichier villes_sup300.csv contient les populations des villes françaises ayant plus de 300 000 habitants.
Le fichier villes_100_300.csv contient les populations des villes françaises ayant entre 100 et 300 000 habitants en 2015 (données INSEE).
Écrire un script permettant de fusionner ces deux tables dans un fichier
villes_sup100.csv.
7.2. Fusionner des tables ayant des attributs différents
Pour fusionner deux tables, il est impératif qu'elles aient au moins un attribut en commun qui servira de pont entre elles.
Cet attribut doit permettre d'identifier de façon unique un enregistrement : on l'appelle un identifiant.
Il existe plusieurs façon de joindre des tables :
| Nom de la fusion | interne | externe gauche | externe droite | externe entière |
|---|---|---|---|---|
| Explications | Prend seulement les enregistrements des deux tables qui sont associables. | Prend tous les enregistrements de gauche et y associe les enregistrement de droite quand c'est possible, sinon complète la table avec la valeur NULL. | Prend tous les enregistrements de droite et y associe les enregistrement de gauche quand c'est possible, sinon complète la table avec la valeur NULL. | Prend tous les enregistrements des deux tables en les associant quand c'est possible, sinon complète la table avec la valeur NULL. |
| Schéma | 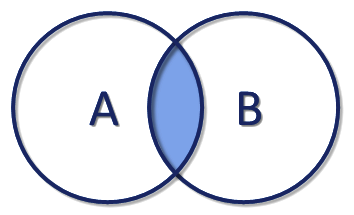 | 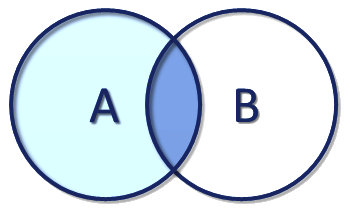 | 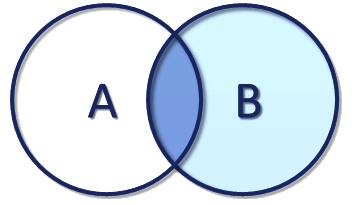 |  |
Exemple :
Nous disposons de deux tables :
| Nom | Courriel |
|---|---|
| PICHO | trailin@new.com |
| MARTIN | rwyt@kitin.com |
| KERROUC | kishimoto@kitin.com |
| MAS | vovivano@not.com |
| Pseudo | Courriel | Orientation politique |
|---|---|---|
| Naruto | kishimoto@kitin.com | extrème gauche |
| AllezLeStade | linkymaster@not.com | droite |
| 123456789 | milou@not.com | droite |
| GenerationM | trailin@new.com | centre |
| Tocamélos | rwyt@kitin.com | gauche |
Ici c'est l'attribut Courriel qui permet cette jointure.
1 - Combien d'enregistrement possèdera cette nouvelle table par une jointure interne ?
2 - Donner les enregistrements obtenus par jointure interne ?
3 - Combien d'enregistrement possèdera cette nouvelle table par une jointure externe gauche ?
4 - Donner les enregistrements obtenus par jointure externe gauche ?
5 - Combien d'enregistrement possèdera cette nouvelle table par une jointure externe droite ?
6 - Donner les enregistrments obtenus par jointure externe droite ?
7 - Combien d'enregistrement possèdera cette nouvelle table par une jointure externe entière ?
8 - Donner les enregistrements obtenus par jointure entière ?